
Data integration is important for leveraging insights and innovation in organizations. However, dealing with large volumes, diverse sources, and complex transformations can be challenging. Enter Dataflow Gen 2, a part of Microsoft Fabric, simplifying the data integration process for streamlined insights and innovation.
Dataflow Gen2
Dataflow Gen2 is the latest data preparation and transformation tool in Microsoft Fabric. It allows you to connect to data from multiple sources, clean and transform it, and then load it into different destinations all through an easy-to-use, low-code interface.
Built on the familiar Power Query experience available in Excel and Power BI, Dataflow Gen2 includes more than 300 built-in data transformation and AI-powered features, making it easier to prepare data without writing complex code.
What’s New?
Dataflow Gen2 now uses the Modern Query Evaluation Engine, which is built on .NET 8 to provide faster, more reliable, and efficient data processing.
Some of the key improvements include:
- Supports 80+ data connectors, including Lakehouse, Warehouse, Azure Data Explorer, SQL Server, Salesforce, and Google Analytics.
- Enabled by default for all newly created Dataflow Gen2 items.
- Delivers improved performance and reliability during data refresh and transformation.
- Offers an optional Partitioned Compute mode (currently in preview) to improve the performance of large file-based data ingestion workloads.
Dataflow Gen 2 is capable of managing diverse data types, including:
- Structured data – CSV files, Excel files etc.
- Semi-structure data – HTML, XML, JSON etc.
- Unstructured data – audio, video, images etc.
Key features of Dataflow Gen2
- Streamlined Authoring – Shorter and simpler Power Query authoring with auto-save and background publishing.
- Flexible Data Destinations – Specify destinations like Fabric Lakehouse, Azure Data Explorer, Synapse Analytics, or Azure SQL Database.
- Enhanced Monitoring – Improved monitoring and refresh history for better dataflow management.
- Pipeline Integration – Seamless integration with data pipelines for orchestration and scheduling.
- High-Scale Compute – Leverages Spark clusters for faster and reliable data processing.
- Exactly-Once Processing (E1P) – Ensures data integrity by preventing duplicates and data loss.
- Self-Service Management – Empowers users with self-service dataflow management without extensive coding.
- Automation and Streamlining – Designed to automate and streamline data integration processes for improved reliability.
- CI/CD and Git Integration-Dataflow Gen2 now comes with built-in CI/CD and Git integration by default for all newly created dataflows.
This allows you to:
- Connect your Dataflow Gen2 project to a Git repository for version control.
Use deployment pipelines to promote dataflows across different environments, such as Development, Test, and Production. - Manage Dataflow Gen2 programmatically using Public APIs, including creating, reading, updating, deleting, scheduling, and monitoring dataflows.
How to create a dataflow?
Follow these steps to create dataflow
Prerequisite
- Obtain a Microsoft Fabric tenant account with an active subscription. Refer Lesson 3 Getting started with Microsoft Fabric.
- Verify that you have a Microsoft Fabric-enabled Workspace set up and ready for use. Refer Lesson 4 Fabric Workspaces and how to create one?
Create a dataflow
- Launch https://app.fabric.microsoft.com
- Navigate to My workspace and click on Dataflow Gen2 under “New item”.
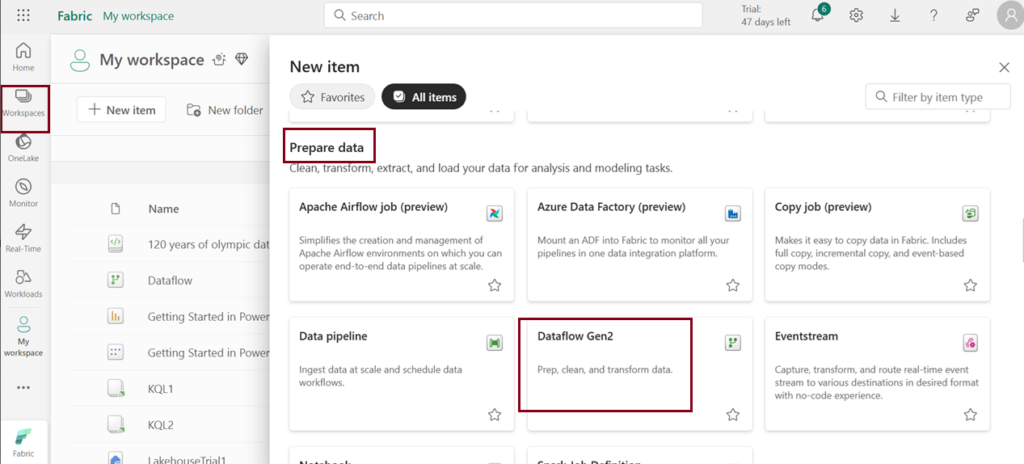
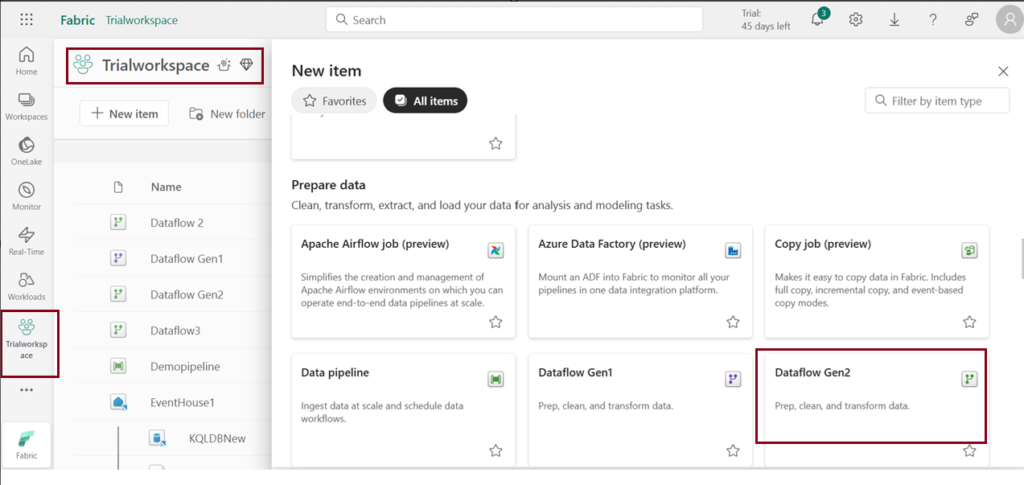
- You can also navigate through the workspace you created. Click on “New item” and choose “Dataflow Gen2”.
- Download the dataset given below and follow the steps below. The dataset is taken from Kaggle.
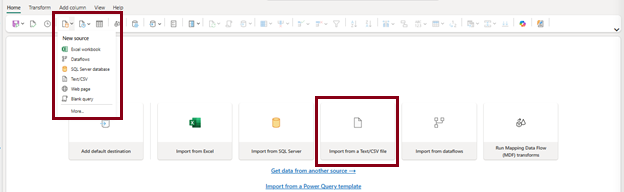
- Select Get Data –> Text/CSV or select Import from a Text/CSV file from home page of the editor to import csv file.
- Upload the given dataset and click next.

- View the table preview and click on “Create.”
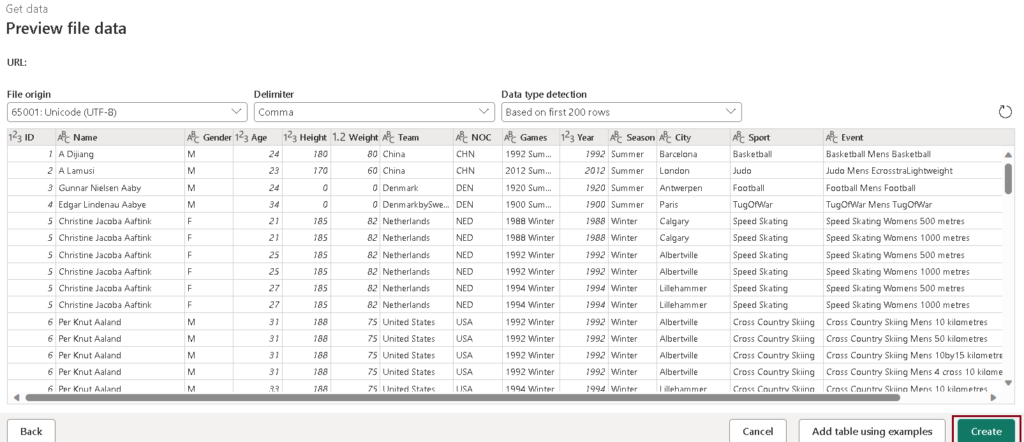
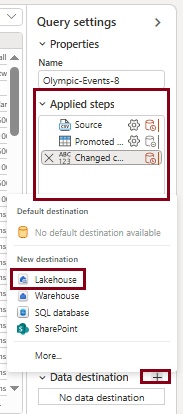
- In the query pane, the Applied steps display the dataset transformations. To add a destination, click the “+” symbol next to “Add destination” and select “Lakehouse.“
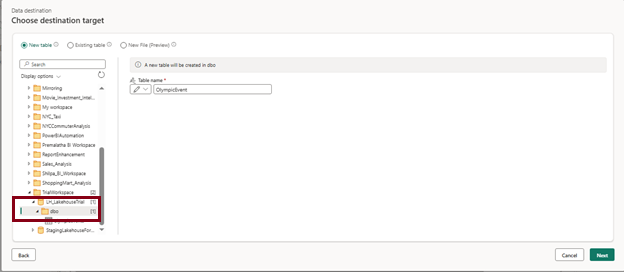
- Select the Lakehouse you want to store the transformed table and select the update method and save your settings.
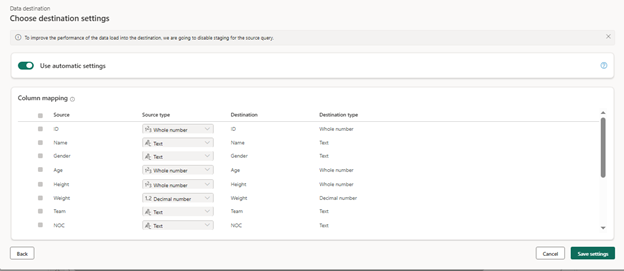
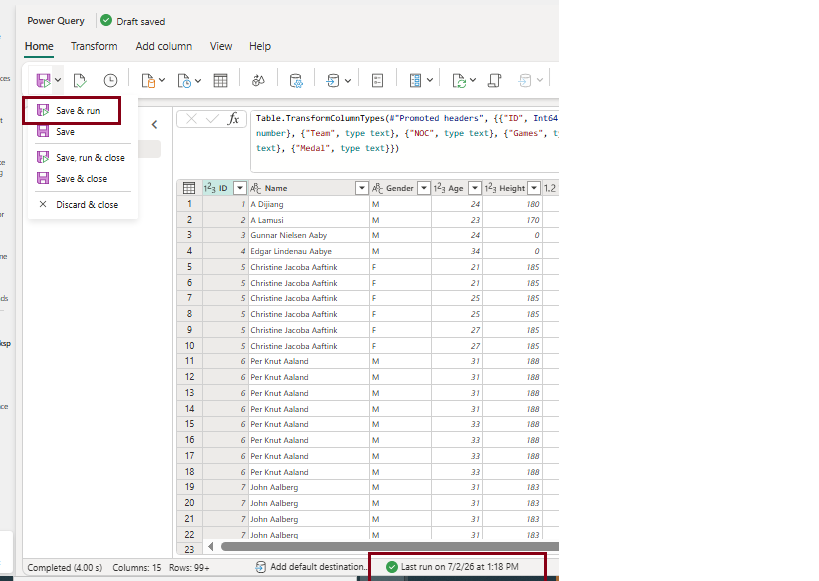
- Click Save Setting Your dataflow has been published in Lakehouse
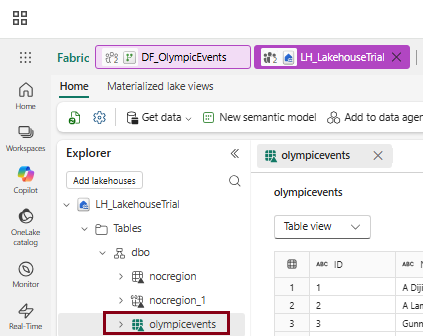
- Click Save and Run to execute the dataflow. Once the process completes successfully, the data will be published to the Lakehouse. Refresh your Lakehouse to verify that the data has been loaded successfully.
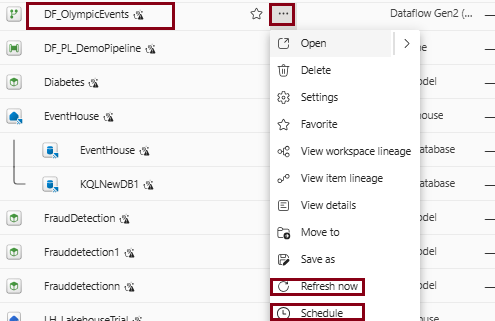
A refresh feature allows you to update your dataflow with the latest data from your sources. The schedule refresh feature automates this process at a specified frequency and time.
Performance : The latest version of Dataflow Gen2 offers significantly better performance and lower costs than earlier versions. These improvements are powered by the Modern Query Evaluation Engine, faster data ingestion through OneLake, and Partitioned Compute (currently in preview), which speeds up the processing of large file-based datasets.
| Tags | Microsoft Fabric |
| Useful links | |
| MS Learn Modules | |
Test Your Knowledge |
Quiz |