
Microsoft Fabric is a new analytics platform that helps with handling and analyzing data. One standout feature is the “lakehouse,” a smart way of managing data that combines the best of both data lakes and data warehouses. With a lakehouse, you can keep and analyze various types of data all in one place, using affordable cloud storage and open formats. It comes with handy features like transactions (keeping track of changes), schema enforcement (ensuring data consistency), and support for business intelligence (helping with data analysis for decision-making).
Microsoft Fabric Lakehouse is built on OneLake, which serves as a unified storage layer. This enables different Fabric experiences such as Data Engineering, Data Science, Data Warehouse, and Power BI to work with the same data without creating multiple copies.
Source: Microsoft learn
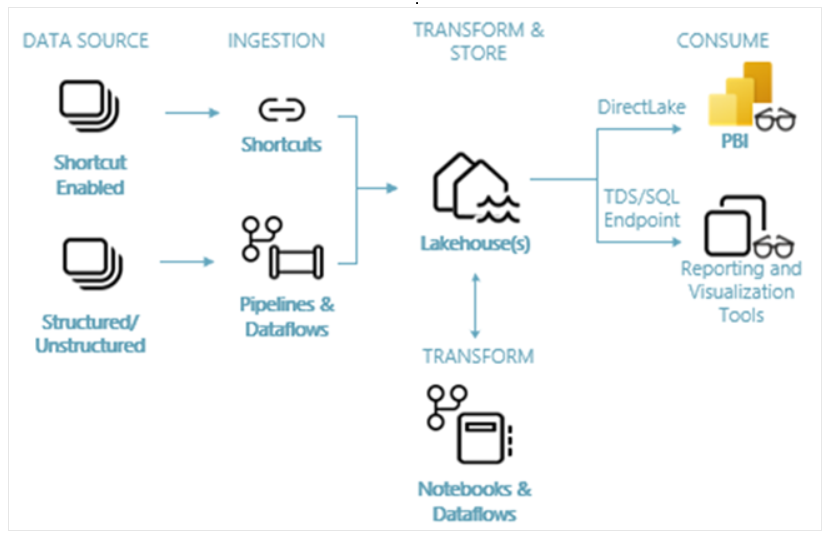
A lakehouse in Microsoft Fabric consists of five layers:
Ingestion Layer
- Gathers data from diverse sources.
- Transforms data into a format suitable for storage and analysis in a lakehouse.
- Accommodates both batch and streaming data.
- Handles structured and unstructured data.
- Sources data from a variety of applications, devices, and sensors.
Storage Layer
- Stores data in open file formats like Parquet or ORC.
- Utilizes cost-effective object storage such as Azure Data Lake Storage or Amazon S3.
- Enables accessibility to the data through a range of tools and languages, including SQL, Python, Scala, R, and more.
- In Microsoft Fabric, Lakehouse data is stored as Delta Lake tables in OneLake, providing ACID transactions, schema evolution, versioning, and improved reliability
Metadata Layer
- Tracks and manages various aspects of data in the lakehouse, including schema, version, lineage, and data quality.
- Facilitates features such as ACID-compliant transactions, schema enforcement and evolution, data validation, and time travel.
- An illustration of a metadata layer is the open-source Delta Lake project.
API Layer
- Offers a unified interface for accessing and processing data within the lakehouse.
- Supports a range of data processing engines like Apache Spark, Apache Flink, or Apache Beam.
- Accommodates data science and machine learning frameworks, such as TensorFlow, PyTorch, or MLlib.
- Includes capabilities for performance optimizations like caching, indexing, and vectorized execution.
Consumption Layer
- Enables users to consume and analyse data within the lakehouse.
- Supports various applications and tools, including business intelligence, data visualization, data science, machine learning, and reporting.
- Incorporates security and governance features such as authentication, authorization, encryption, and auditing.
- Every Fabric Lakehouse includes a SQL Analytics Endpoint, allowing users to query Lakehouse tables using T-SQL. Power BI can also connect using Direct Lake for high-performance analytics.
The lakehouse architecture also allows data to be consolidated and unified for different use cases, such as engineering, data science, machine learning, and business intelligence, in a single system.
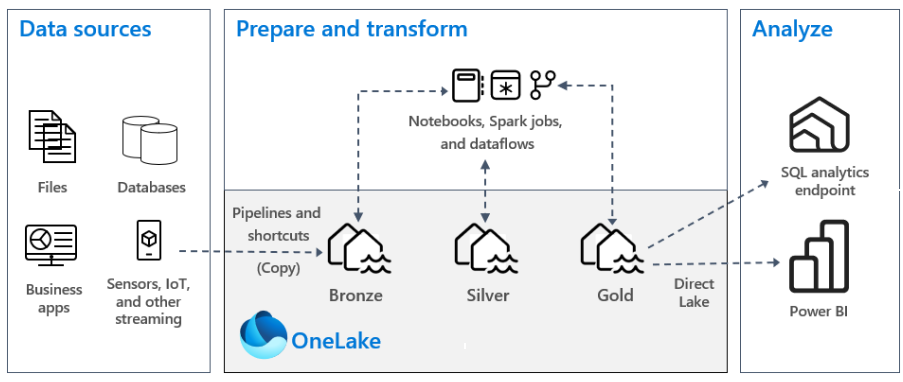
Medallion Architecture
In the lakehouse architecture, data undergoes a continuous process of incremental improvement, enrichment, and refinement as it travels through various stages of staging and transformation. This particular approach is commonly denoted as a medallion architecture.
Source: Microsoft learn
The medallion architecture is like a step-by-step process for handling data in a lakehouse. Databricks suggests using different layers to create a reliable source of data for businesses. This method makes sure data is trustworthy and goes through checks and improvements before being stored in a way that makes it easy to analyze.
The medallion architecture typically involves three main layers, often referred to as bronze, silver, and gold.
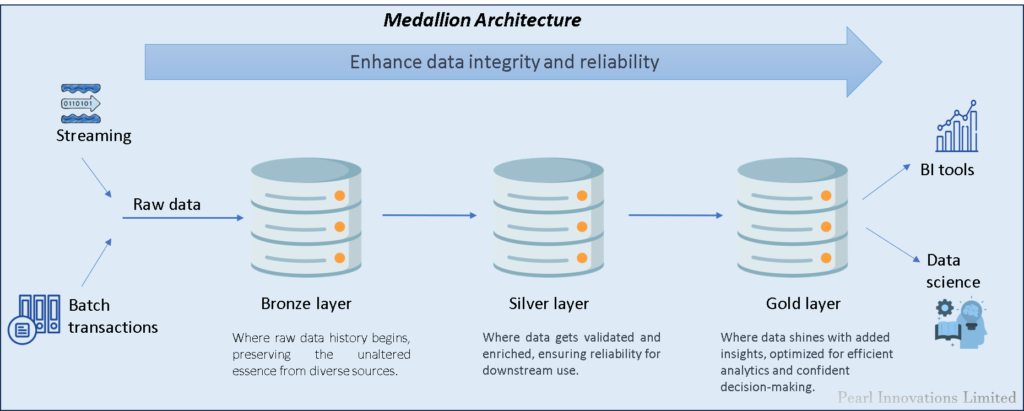
Here’s a breakdown of each layer:
Bronze Layer (Raw Zone)
Description: This is where raw, untouched/unvalidated data is initially stored.
Characteristics:
- Data in its original form, straight from various sources without much processing. Data here is unvalidated.
- It preserves the raw state of the original data source.
- The volume of data in this layer increases gradually over time.
- Data is a combination of both streaming (continuous flow) and batch (grouped) transactions.
Purpose: Acts as the starting point for data ingestion, holding the unaltered source data.
Silver Layer (Enriched Zone)
Description: In this layer, the data undergoes validation and basic processing.
Characteristics:
- Validation checks for accuracy, consistency, and completeness are applied. Metadata may be added.
- Data in this layer can be trusted for downstream analytics.
Purpose: Ensures that the data is reliable and conforms to specific quality standards.
Gold Layer (Curated Zone)
Description: The enriched layer where data is enhanced with additional information, transformations, and business logic.
Characteristics: Optimized for efficient analytics, may include aggregated or calculated data.
Purpose: Represents a high-quality version of the data ready for consumption, often serving as a trusted source for decision-making.
Best Practice: In Microsoft Fabric, Gold layer data is commonly consumed through Power BI Direct Lake or a Fabric Warehouse, depending on reporting and business requirements.
In summary, the three layers of the medallion architecture (bronze, silver, and gold) represent different stages in the data processing pipeline, with each stage adding value and improving the quality of the data for various purposes, from raw storage to enriched analytics-ready information.
| Tags | Microsoft Fabric |
| Useful links | |
| MS Learn Modules | |
Test Your Knowledge |
Quiz |