
Delve into the robust features of SynapseML, an open-source library on Apache Spark, streamlining machine learning workflows. Follow our blog for a hands-on journey, mastering the art of training models in the Fabric Data Science environment, illustrated through a practical Iris dataset example.
Synapse ML
SynapseML, formerly MMLSpark, is an open-source library designed for the creation of scalable and efficient machine learning (ML) pipelines. Built on the Apache Spark distributed computing framework, SynapseML simplifies complex ML tasks, offering simple, composable, and distributed APIs for a range of applications including text analytics, computer vision, anomaly detection, and more. The library seamlessly integrates with SparkML/MLLib, enabling the embedding of SynapseML models into existing Apache Spark workflows.
Key features of Synapse ML
Some of the key features of SynapseML are
- Unified API – SynapseML simplifies machine learning on Apache Spark by offering a unified API for diverse frameworks and tasks such as text analytics and computer vision.
- Azure AI Services Integration – SynapseML seamlessly integrates with Azure AI services, providing access to pre-built models and customizable solutions for various domains. his integration enables users to leverage the power of Azure’s intelligent services within the SynapseML framework.
- ONNX Support – SynapseML supports the Open Neural Network Exchange (ONNX) standard, facilitating the exchange of neural network models across diverse platforms and tools. This support enables interoperability, allowing users to use models from various machine learning ecosystems within the SynapseML environment.
- Responsible AI Systems – SynapseML emphasizes the development of responsible AI systems by incorporating tools for model interpretability, fairness, and privacy. These features enable data scientists and developers to understand model predictions, address biases, and ensure ethical and privacy-conscious use of machine learning models.
How to train model with SynapseML?
Follow the steps to train model with SynapseML
Prerequisites
- Launch https://app.fabric.microsoft.com/
- Sign in to Microsoft Fabric with your subscription or trial account. Refer Lesson 3 – Getting started with Microsoft Fabric – Pearl Innovation
Steps
- Navigate to the menu bar on the left side and choose “Workspaces” to create new workspace.
- Download the dataset. Taken from Iris – UCI Machine Learning Repository.
- Create Lakehouse and load the given dataset.
- Click Open notebook -> New notebook to create new notebook.
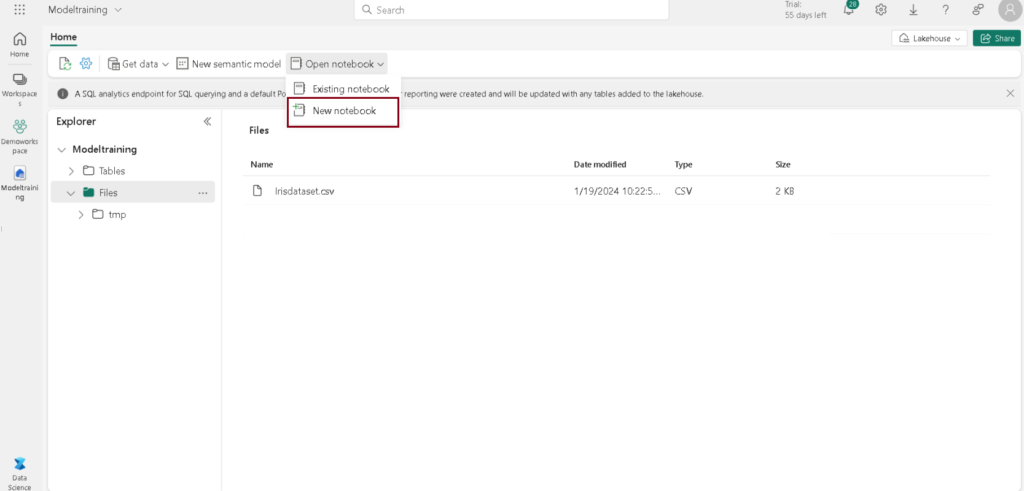
- Within a few seconds, a new notebook will open, comprising a single cell. Notebooks consist of cells that can contain either code or markdown (formatted text).
Set up the environment
- Import SynapseML libraries and initialize your spark session.

Ingest data
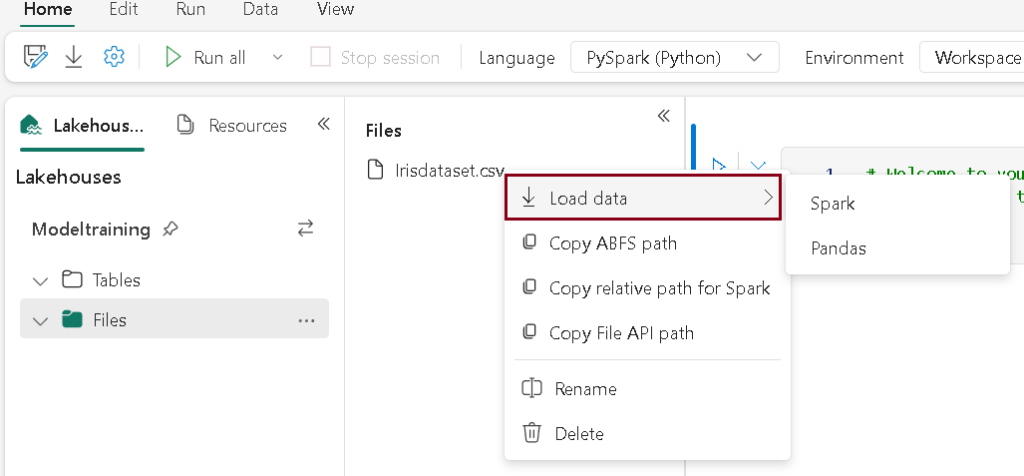
- Click on the ellipsis icon next to the desired dataset under “Files,” then select “Load Data” — > “Spark”. It automatically generates Python script.
- Click Run to run the script.
Selecting Features and Splitting Data
Select relevant features for the model, including the label column (“target”). Split the data into training and testing sets.

Train a Model
- Training a model involves teaching it to make predictions based on input data, adjusting its parameters to minimize prediction errors during the learning process.
- The given code line utilizes Synapse ML’s TrainClassifier module to fit a logistic regression model on a Spark DataFrame (‘train’) with the specified column as the label for classification.

Model prediction on test data
- Model prediction on test data involves using a trained machine learning model to generate predictions for the target variable using a separate set of data reserved for testing, with the results typically stored in a designated DataFrame.
- The given code the trained model to predict outcomes on the test dataset, and the results are stored in the `prediction` DataFrame.

Evaluating the Model
- Assessing the model’s performance involves evaluating its accuracy by comparing its predictions to the actual outcomes on a validation or test dataset.
- Using Synapse ML’s ComputeModelStatistics, this code computes and displays the accuracy metrics by comparing the model’s predictions on the test set with the actual outcomes.

Result
The displayed result indicates that the model achieved an accuracy of approximately 87.88% on the test dataset, implying it correctly predicted outcomes for that proportion of the data.

This example demonstrates a basic workflow for training a machine learning model using SynapseML in a Spark environment. The code shows how to read in data, select features, split data, train a model, and evaluate its performance.
| Tags | Microsoft Fabric |
| Useful Links | |
| MS Learn Modules | |
Test Your Knowledge |
Quiz |