
In today’s world of managing data, it’s crucial to move data seamlessly and efficiently. Microsoft Fabric’s Data Pipelines, an advanced version of Azure Data Factory, lead the way in making this process efficient. This blog is your go-to guide for understanding and creating Data Pipelines, helping you optimize your data integration projects.
Data Pipelines in Microsoft Fabric
In Microsoft Fabric, data pipelines serve as a means to design and control data ingestion and transformation processes through a user-friendly interface. These pipelines enable the utilization of diverse data sources (e.g., Azure SQL database, Blob Storage, Data Lakehouse) and the application of various activities (e.g., Copy Data, Merge Queries, Dataflow Gen2) for extract, transform, and load (ETL) operations. Additionally, scheduling and monitoring of data pipelines are seamlessly handled through Microsoft Fabric’s Data Factory.
The activity list has grown well beyond Copy Data, Merge Queries, and Dataflow Gen2. Pipelines can now also orchestrate dbt jobs (SQL-based transformations), Fabric notebooks, Spark job definitions, stored procedures, SQL scripts, and Apache Airflow DAGs for teams who prefer code-first orchestration in Python. There’s also a separate, simpler item type called Copy job, purpose-built for straightforward source-to-destination ingestion without needing a full pipeline.
Separately, for near real-time replication of an operational database straight into OneLake, Microsoft now recommends Mirroring rather than a pipeline .we will discuss more on mirroring in future blogs.
Key features of data pipelines in Microsoft Fabric
Some of the key features of data pipelines in Microsoft fabric are
- User-Friendly Interface – Easily create and manage data ingestion and transformation tasks through an intuitive graphical user interface.
- Seamless Integration with Microsoft Fabric Artifacts – Data pipelines seamlessly connect with other Microsoft Fabric artifacts, facilitating easy linking to the Lakehouse, Fabric Data Warehouse, or execution of Data Engineering notebooks.
- Pipeline Templates – Pre-defined templates for common tasks reduce development time, enabling quick initiation and completion of data integration projects.
- Built-in AI Capabilities – Integration of artificial intelligence automates common data integration tasks, enhancing efficiency in data processing.
- Quick Data Copy – The Copy Assistant simplifies and accelerates the data copying process, providing a guided approach to connect to various data sources and destinations.
- Flexible Triggers (new in 2026) – Run pipelines on a schedule, or trigger them automatically based on events such as a new file arriving in a data lake or a change in a source database.
- Reusable via Parameters (new in 2026) – Parameterize connections and file paths so the same pipeline can process different datasets or environments without duplicating it.
How to create Data Pipelines in Microsoft Fabric?
Follow the steps to create data pipelines
Prerequisite
- Obtain a Microsoft Fabric tenant account with an active subscription. Refer Lesson 3 Getting started with Microsoft Fabric.
- Verify that you have a Microsoft Fabric-enabled Workspace set up and ready for use. Refer Lesson 4 Fabric Workspaces and how to create one?
Steps to create data pipeline
- Launch https://app.fabric.microsoft.com/
- Click on the Fabric icon at the bottom of the page, then choose Power BI. This will take you directly to the Power BI home page.

- You have two options to create a Data Pipeline. You can click Create option on the left side of the page and choose on “Pipeline” under Data Factory.
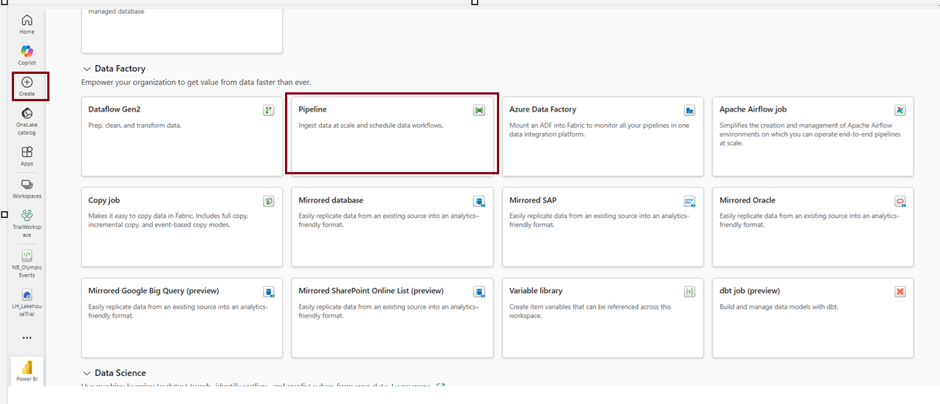
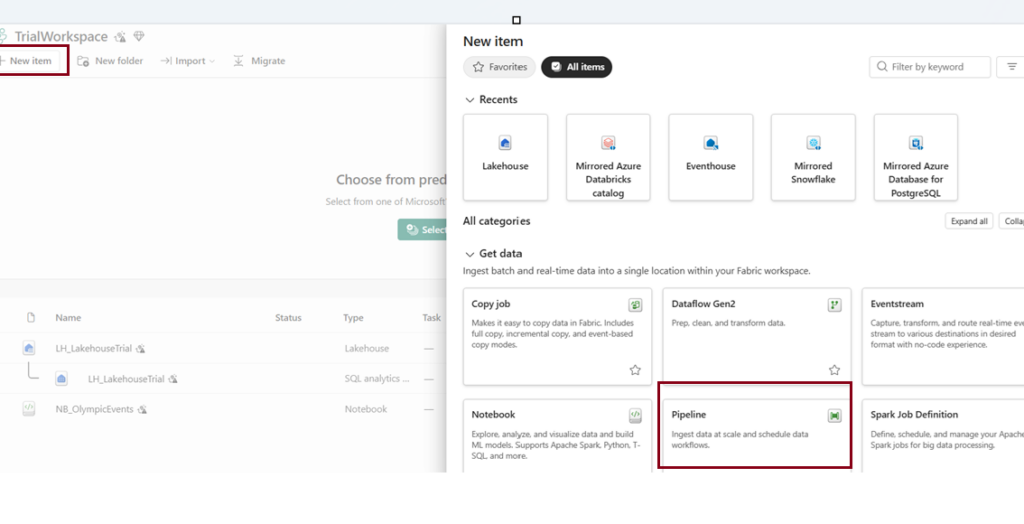
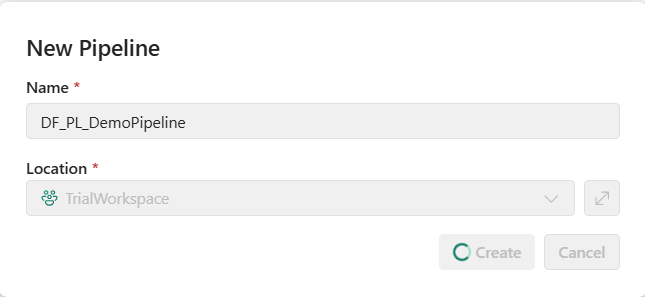
The homepage of Demopipeline has the following appearance.
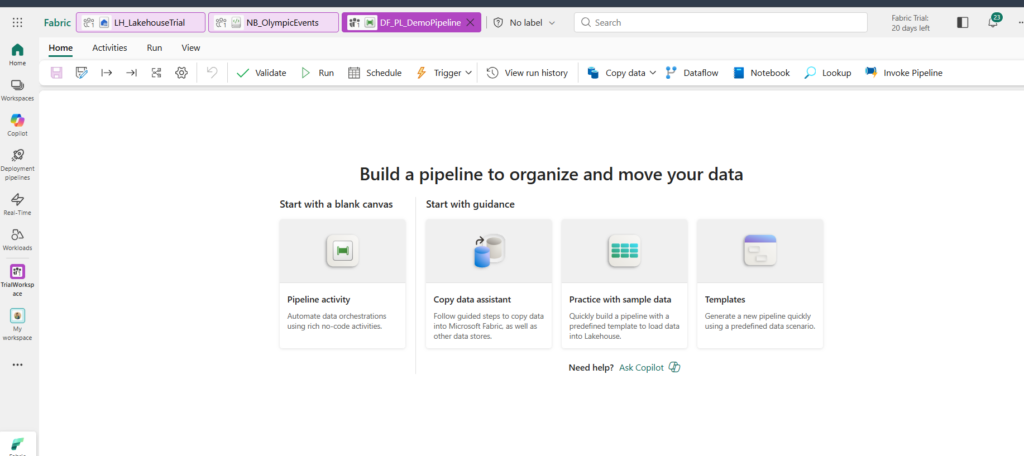
Add pipeline activity
Pipeline activities represent the individual steps or tasks performed on data to achieve specific goals, such as moving, transforming, or analyzing data. The types of activities may vary based on data sources, destinations, and processing methods.
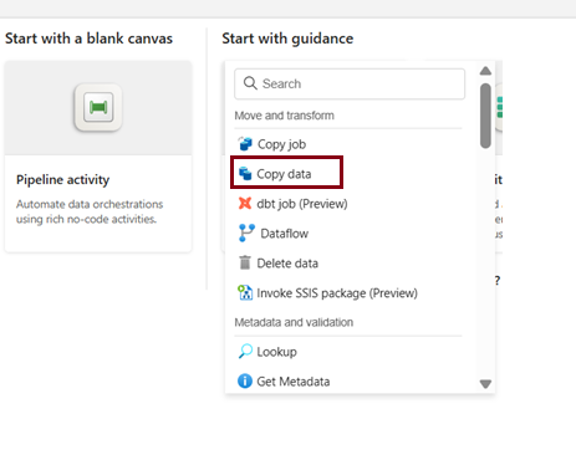
Copy data
You can connect to various data sources and destinations and choose from sample data sources for a quick start. The step-by-step process guides you to configure data load options, creating a new pipeline activity for streamlined data movement across different stores like Azure SQL database, Blob Storage, or Data Lakehouse.
If your goal is only a simple source-to-destination copy – no other activities involved consider creating a standalone Copy job item instead of a Copy Data activity inside a pipeline. It’s a faster path for that specific scenario. Now we have created a Copy Data activity
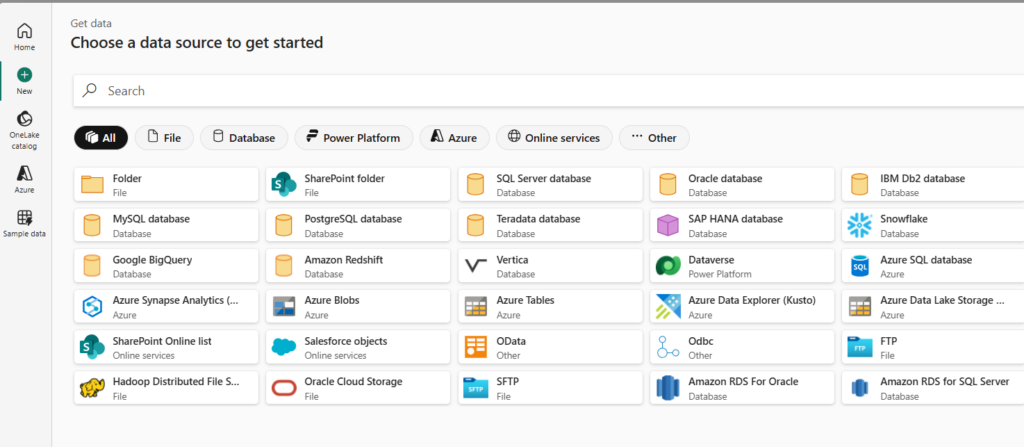
Choose a task to start
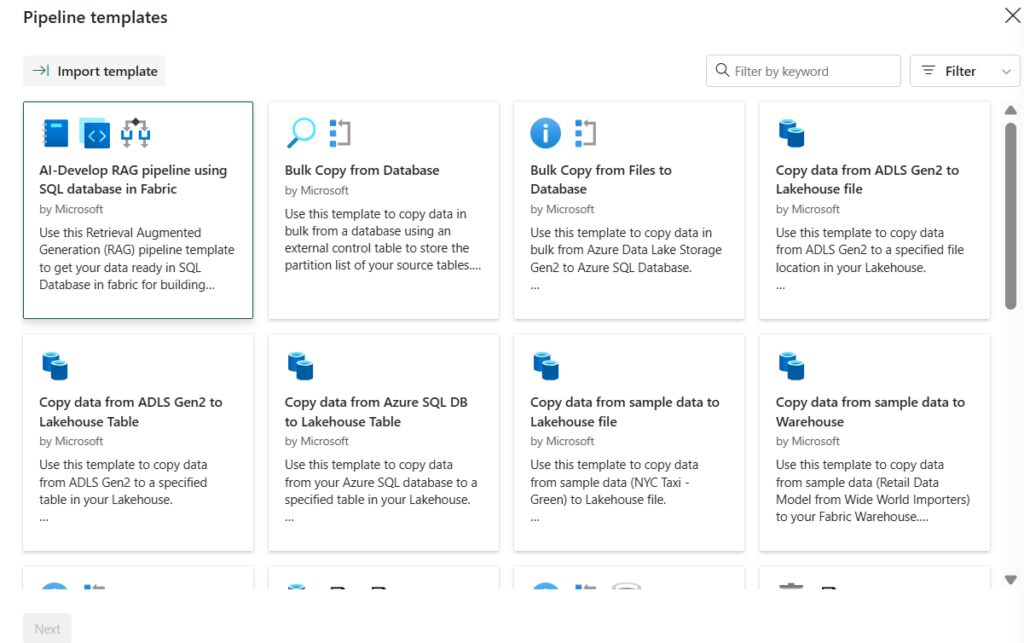
Accelerate your pipeline creation process by leveraging ready-made templates designed for quick starts. These pre-defined pipelines not only streamline the building of data integration projects but also contribute to increased efficiency by significantly reducing development time.
Scroll down for more options in templates.
| Tags | Microsoft Fabric |
| Useful links | |
| MS Learn Modules | |
Test Your Knowledge |
Quiz |